





















ICTコラム
世界で繰り広げられるロボット基盤モデル開発記事ID:D40074

さまざまな環境やタスクに対応可能な知能を持ったロボットの研究開発が加速しています。ロボットの知能の鍵となるAIモデルがロボット基盤モデルです。本連載(全3回)の2回目は、研究開発が特に進むVLAと呼ばれるロボット基盤モデルについて解説します。加えて、さらなる性能向上のために乗り越えるべき課題と対応、日本の取り組みについても触れ、ロボット基盤モデルの開発動向を解説します。
研究開発が進むVLA
2025年の夏頃から世界で「フィジカルAI」という技術用語に注目が集まっています。これはロボットなどの物理的な身体を持ち、現実世界を理解しながら動作するAIのことを指します。フィジカルAIの進展、つまり、ロボットが物理的な環境で対応可能なタスク(作業・課題)を拡大するための鍵となるのが、前回ご説明した、幅広いタスクに対応できる汎用的な知識や行動能力を獲得するように設計されたAIモデルであるロボット基盤モデルです。
ロボット基盤モデルの中でも、特にVLA(Vision-Language-Action Model)の研究が進展しています。名前の通り視覚、言語、行動を統合して処理を行うVLAは、与えられた指示とカメラ画像などのデータを入力すると、ロボットが実行すべき次の行動を出力するモデルです。例えば、「ゴミをゴミ箱に捨てて」という指示とテーブル上を撮影した画像を入力すると、ロボットの腕の関節を10度曲げて回転するなどの具体的な動作指令を出力します(図参照)。
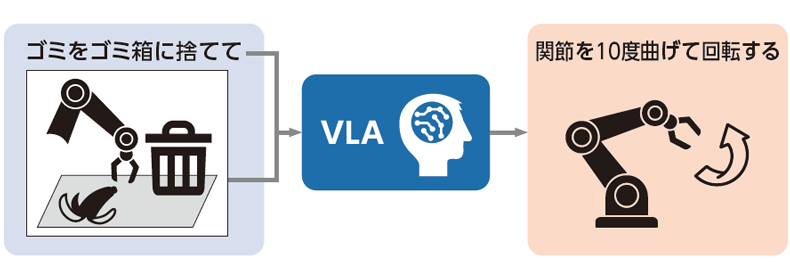
【図:VLA搭載モデルの仕組み】
従来のロボットは、①指示を理解するAI、②画像認識AI、③認識結果を基に行動を決定するAIなどの複数のAIが連携して動作していました。そのため、すべてのAIが正しく動かないと、動作が遅くなったり失敗したりしていました。VLAではこれらの機能を一つのAIに統合し、視覚・言語を正しく理解した上での行動判断が可能となりました。
ロボット基盤モデルの代表例
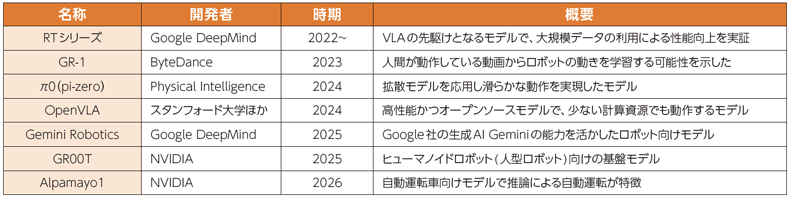
【表:主なロボット基盤モデル】
世界ではさまざまなロボット基盤モデルが開発されています(表参照)。ここでは代表的な三つのモデルを紹介します。
VLAの先駆けとして Google DeepMind社のRT(Robotics Transformer)があります。特に、RT-2は現在のVLA開発の流れを作った初期のモデルです。ロボットの動作データに加え、インターネット上の膨大な言語・画像データも学習しています。これにより、ロボットがインターネット上の知識を活用して人間の指示を理解し、動作できることが示されました。例えば、「疲れた時の飲み物」と言われると「エナジードリンク」を掴む動作が可能になりました。
もう一つの例はPhysical Intelligence社が開発したπ0(pi-zero)です。このモデルは画像や動画生成AIで広く用いられる拡散モデル※1の応用技術を取り入れています。画期的な点はπ0搭載ロボットが非常に滑らかに動作することです。従来ロボットの動作がカクカクしていた点が改善され、ロボットが洗濯物を洗濯機から取り出し、畳むなどの精緻な動作が可能になりました。
最後にOpenVLAを紹介します。従来のVLAは、特定の研究組織がモデルを独占し、また、動作には大規模な計算資源※2が必要でした。OpenVLAは高性能かつ誰でも使いやすいオープンソース※3VLAとして開発されました。少ない計算資源でも動作し、オープンソースであるため世界中の研究者が利用・改変しやすくなりました。これによりロボット研究への参入が容易になりました。
表の通り、VLAの研究開発はこの2~3年で始まったばかりで、初期段階と言えます。今後も生成AI技術の進展とともに、ロボット基盤モデルの発展が期待されます。
さらなる性能向上のための課題
ロボット基盤モデルによりロボットの汎用性は向上しましたが、人間と同等にさまざまな状況やタスクに対応するレベルに達していません。課題の一つは学習データの量と質です。一般にロボットの動作データはインターネットなどには公開されておらず、大量の学習データを収集することは容易ではありません。また、学習データはロボットが動作する実環境での取得が望ましいですが、現状ではロボット開発用の実験環境で取得されたデータが多く、質にも課題があります。
この課題の解決策として、多くの人手で実環境のデータ収集を試みる事例があります。例えば、中国のAgiBot社ではロボットの実環境データを取得するために4,000平方メートル超の専用施設を開設しています。大量に雇用した人間が実際のロボットを操作し、その操作データをモデルの学習に用います。
もう一つの解決策はシミュレーター(仮想の環境を再現するシステムなど)の活用です。コンピューター上にロボットが動作する実環境を模した仮想環境を構築し、ロボットを動作させ、そのデータを学習に利用します。シミュレーターは物理環境を準備する必要がないため、低コストかつ試行錯誤が容易です。また、実環境では取得が難しいデータ(例:ロボットと何かが衝突するデータ)を容易に収集できる利点があります。
日本の取り組み
日本におけるロボット基盤モデル開発の事例は、自動運転車向けのVLAの開発に取り組むTuring社などがありますが、限定的です。先行する米国や中国に比べ後れをとっており、打開に向けた取り組みが進んでいます。
一つ目は政府支援です。日本政府は2025年12月に人工知能基本計画を閣議決定しました。この中で「フィジカルAIの研究開発及び実証を戦略的かつ統合的に促進」と明記しました。国産の基盤モデルの開発を国が支援し、官民挙げた取り組みが今後進展する見込みです。
二つ目はAIロボット協会(AIRoA)の取り組みです。日本のさまざまな業界の企業が垣根を越えて連携し、基盤モデル開発に必要なデータの収集・管理を行い、開発を推進しています。加えて、これらのデータとモデルを公開し、さまざまな事業者が活用することで、データが集まりやすい仕組み「ロボットデータエコシステム」の構築を目指しています。
そのほか、フィジカルAIやロボット基盤モデル開発への参入を表明する日本企業も増えています。例えば、産業用ロボット大手のファナック(FANUC)社はNVIDIA社と協業して、産業用ロボットのフィジカルAI実装を促進すると発表しています。今後、日本がロボットとAIの分野でどのような地位を築いていくか注目されます。
- ※1 拡散モデル
- 画像生成AIに採用されている学習モデルの一つで、雑多なノイズを除去して美しい画像を作り出すことができる。ここでは、拡散モデルの派生技術「flow matching」と呼ばれる技術が使われている。
- ※2 計算資源
- コンピューターの処理の能力のことで、特にAIモデルでは大量の計算を実行するためにGPU(Graphics Processing Unit)と呼ばれる装置が大量に必要となる。
- ※3 オープンソース
- ソフトウェアの設計図であるソースコードが公開されており、決められたライセンスの範囲で誰でも自由に利用・修正・再配布できるソフトウェアのこと。

株式会社日本総合研究所 先端技術ラボ 次長兼エキスパート。2011年、日本総合研究所に入社。2018年よりAI技術の調査・研究を担当し、SMBCグループ向けのAI技術を用いた実証実験に携わる。現在、生成AIを中心としたAI技術の中長期的な動向に関する技術リサーチとAIの調査・研究チームのマネージャーも担当。共著に「AI時代の人的資本経営」(日本能率協会マネジメントセンター、2025年)。
関連記事


- 電話応対でCS向上コラム(355)
- 電話応対でCS向上事例(286)
- ICTコラム(138)
- デジタル時代を企業が生き抜くためのリスキリング施策(3)
- 2024年問題で注目を集める物流DXの現状とこれから(3)
- 女性の健康、悩みに寄り添うフェムテックとは(3)
- 健康経営のためにも取り入れたいスリープテック(3)
- ノーコード・ローコード開発の導入ポイント(3)
- 偽・誤情報や誹謗中傷によるトラブルを防ぐために(3)
- AIロボットの現状と将来性(3)
- ひとり情シス時代を中小企業が乗り越えるための対処法(1)
- SDGs達成にも重要な役割を担うICT(3)
- 人生100年時代をICTで支えるデジタルヘルス(3)
- 働き方改革と働き手不足時代の救世主「サービスロボット」の可能性(3)
- ICTで進化する防災への取り組み「防災テック」(3)
- ウイズ&アフターコロナで求められる人材育成(3)
- AI-OCRがもたらすオフィス業務改革(3)
- メタバースのビジネス活用(3)
- ウェブ解析士に学ぶウェブサイト運用テクニック(46)
- 中小企業こそ取り入れたいAI技術(3)
- 日本におけるキャッシュレスの動向(3)
- DXとともに考えたい持続可能性を図るSX(3)
- 「RPA(ソフトウェア型ロボット)」によるオフィス業務改革(6)
- 「農業×ICT」で日本農業を活性化(3)
- コロナ禍における社会保険労務士の活躍(4)
- コールセンター業務を変革するAIソリューション(3)
- ICTの「へぇ~そうなんだ!?」(15)
- 子どものインターネットリスクについて(3)
- GIGAスクール構想で子どもたちの学びはどう変わる?(3)
- Z世代のICT事情(3)
- 企業ICT導入事例(189)
- ICTソリューション紹介(100)
ICTコラム 新着記事




